Context-Free Grammars are just one kind of grammar. In this section
we briefly consider an even more restricted kind of grammar, known as a
Regular Grammar.
As one would expect, the language of a Regular Grammar is a Regular
Language. In fact, any regular language has a regular grammar, so now we
have a four ways to show a language is regular: find an NFA, a DFA, a
regular expression, or a regular grammar.
Definition
A Regular Grammar is a context-free grammar in which all
rules have one of the following forms: > | Production Shape | (In
English) | | —————- | —————————————— | | \(X\to aY\) | Nonterminal goes to terminal +
nonterminal | | \(X\to Y\) |
Nonterminal goes to nonterminal | | \(X\to
a\) | Nonterminal goes to terminal | | \(X\to \epsilon\) | Nonterminal goes to empty
string |
Example
The grammar >\[
>\begin{array}{lcl}
> S & \to & 0S\ |\ 1A\\
> A & \to & 1A\ |\ \epsilon\\
> \end{array}
>\] >is a regular grammar (as well as being a context-free
grammar).
Every Regular
Language has a Regular Grammar
Suppose we have a regular language \(L\). There must be an NFA for \(L\); it is fairly straightforward to turn
an NFA recognizing \(L\) into a regular
grammar that can produce any string in \(L\).
The trick is to have one nonterminal for each state in the NFA. Each
nonterminal will produce all the strings in the language of the
corresponding NFA state (i.e., the strings that would be accepted if we
started at that NFA state instead of at the start state.) The
definitions of these nonterminals can then be read off from the
transitions of the NFA.
Example
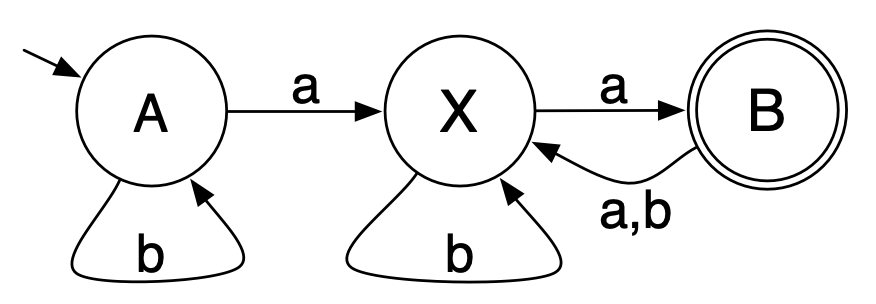
Consider the following state machine: > If we look at state \(X\), we see that the strings that would be
accepted starting at state \(X\) either: > >- start with an \(a\) and have a remainder that can be
accepted starting from state \(B\), or
else >- start with \(b\) and
continue a remainder that can be accepted starting from state \(X\). > Similarly, the strings we can
accept starting from state \(B\) either
has an \(a\) or \(b\) followed by a string that can accept
starting from state \(X\), or else is
the empty string (which would accept since \(B\) is an accepting state). > In this
fashion, we can construct a (regular!) grammar for the languages of all
the states: >\[
>\begin{array}{lcl}
> A & \to & aX\ |\ bA\\
> X & \to & aB\ |\ bX\\
> B & \to & aX\ |\ bX\ |\ \epsilon\\
> \end{array}
>\] and since the language of a state machine is (by
definition) the language of its start state, this grammar (where \(A\) is the start symbol) produces exactly
the strings in the language of this state machine.
One can also go the other direction; any regular grammar can be
directly translated into an NFA with one state per nonterminal:
Example
The regular grammar >\[
>\begin{array}{lcl}
> S & \to & 0S\ |\ 1A\\
> A & \to & 1A\ |\ \epsilon\\
> \end{array}
>\] can be translated into the following NFA: > Note that
the state corresponding to start symbol \(S\) is the start state, and state(s) that
can produce the empty string are accepting states.
Be Careful with Terminology
A context-free grammar is a grammar whose rules have a
nonterminal on the left-hand-side.
A context-free language is a language (set of strings) that
can be described with a CFG (or PDA)
A regular grammar is a grammar whose rules are particularly
simple (all having one of the four allowed forms).
A regular language is a language (set of strings) that can
be described with a regular grammar (or NFA, DFA, regex).
Every regular grammar is also a context-free grammar, so every
regular language is also a context-free language.
Similarly, a grammar can be context-free but not regular, and a
language can be context-free but not regular.
What is slightly less obvious is that a non-regular grammar can
describe a regular language!
Example
The grammar >\[
>\begin{array}{lcl}
> S & \to & SS\ |\ 1\\
> \end{array}
>\] is not a regular grammar (the rule \(S\to SS\) is not one of the allowable forms
for a regular grammar), but the language of this grammar is \(\{\ 1^n\ |\ n\geq 1\ \ \}\), which is
easily seen to be regular. > How is this possible? Well, a language
is regular iff it can be described by at least one regular grammar,
e.g., >\[
>\begin{array}{lcl}
> S & \to & 1S\ |\ 1\\
> \end{array}
>\] The definition of regular language doesn’t say anything
about whether there might be non-regular (“unnecessarily complex”)
grammars for the language too.
 > If we look at state \(X\), we see that the strings that would be
accepted starting at state \(X\) either: > >- start with an \(a\) and have a remainder that can be
accepted starting from state \(B\), or
else >- start with \(b\) and
continue a remainder that can be accepted starting from state \(X\). > Similarly, the strings we can
accept starting from state \(B\) either
has an \(a\) or \(b\) followed by a string that can accept
starting from state \(X\), or else is
the empty string (which would accept since \(B\) is an accepting state). > In this
fashion, we can construct a (regular!) grammar for the languages of all
the states: >\[
>\begin{array}{lcl}
> A & \to & aX\ |\ bA\\
> X & \to & aB\ |\ bX\\
> B & \to & aX\ |\ bX\ |\ \epsilon\\
> \end{array}
>\] and since the language of a state machine is (by
definition) the language of its start state, this grammar (where \(A\) is the start symbol) produces exactly
the strings in the language of this state machine.
> If we look at state \(X\), we see that the strings that would be
accepted starting at state \(X\) either: > >- start with an \(a\) and have a remainder that can be
accepted starting from state \(B\), or
else >- start with \(b\) and
continue a remainder that can be accepted starting from state \(X\). > Similarly, the strings we can
accept starting from state \(B\) either
has an \(a\) or \(b\) followed by a string that can accept
starting from state \(X\), or else is
the empty string (which would accept since \(B\) is an accepting state). > In this
fashion, we can construct a (regular!) grammar for the languages of all
the states: >\[
>\begin{array}{lcl}
> A & \to & aX\ |\ bA\\
> X & \to & aB\ |\ bX\\
> B & \to & aX\ |\ bX\ |\ \epsilon\\
> \end{array}
>\] and since the language of a state machine is (by
definition) the language of its start state, this grammar (where \(A\) is the start symbol) produces exactly
the strings in the language of this state machine.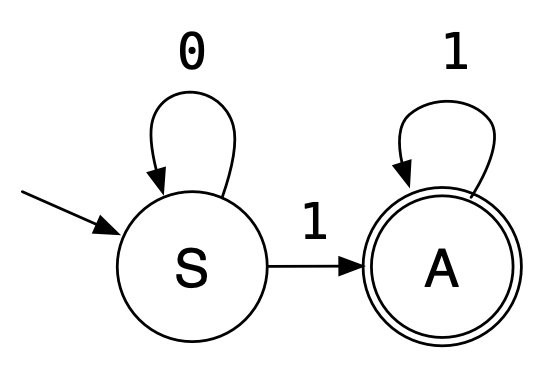 > Note that
the state corresponding to start symbol
> Note that
the state corresponding to start symbol